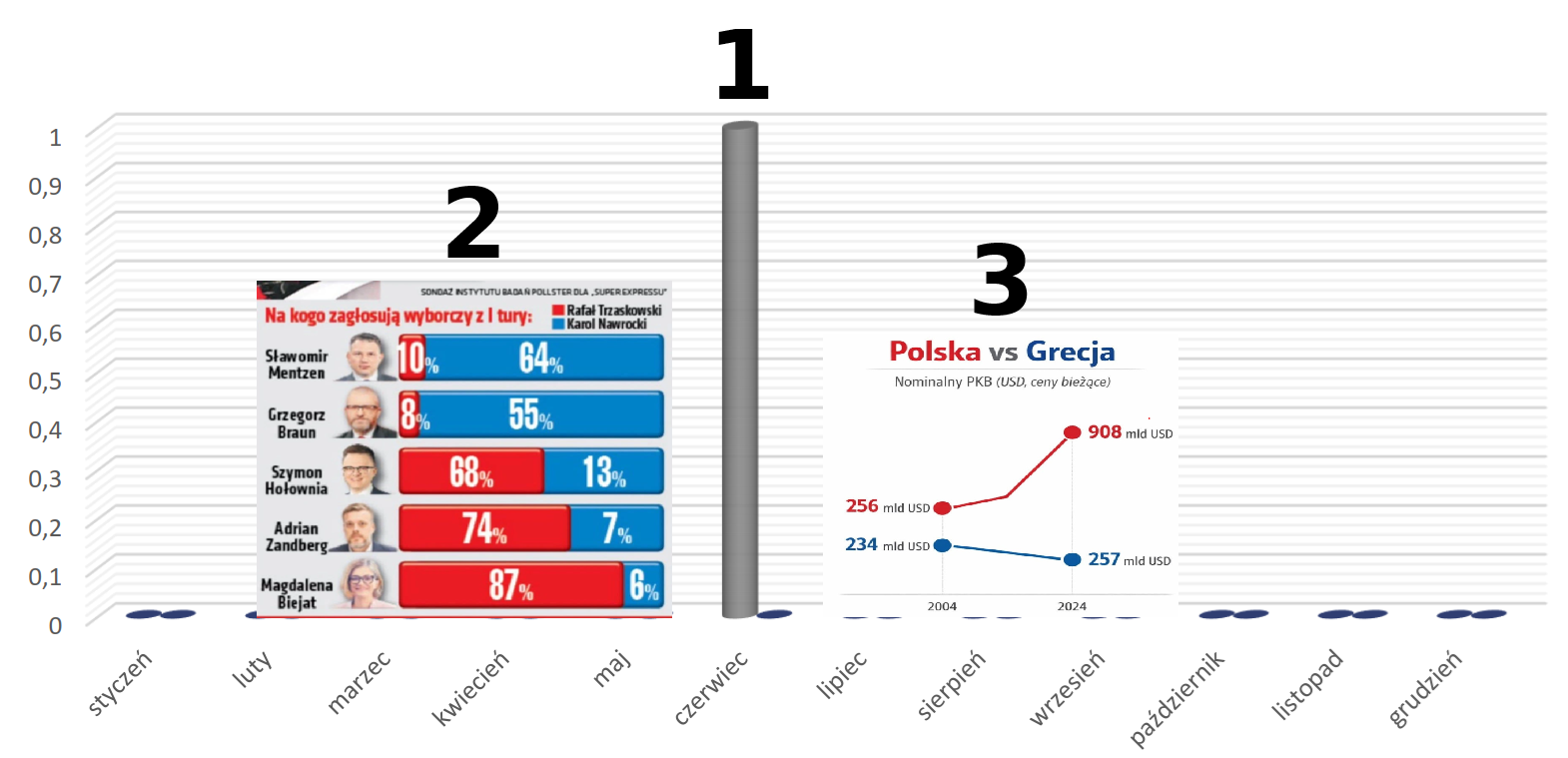
Podsumowanie plebiscytu na najgorszy wykres 2025 roku
Być może niektórzy czytelnicy pamiętają plebiscyty na najgorszy wykres roku, które prowadził profesor Przemysław Biecek. Niestety, parę lat temu przestał ...
Wizualizacja danych
Podsumowanie plebiscytu na najgorszy wykres 2025 roku
Być może niektórzy czytelnicy pamiętają plebiscyty na najgorszy wykres roku, które prowadził profesor Przemysław Biecek. Niestety, parę lat temu przestał ...

Wizualizacja danych
O liczbach, które bolą.
Technologicznie pędzimy naprzód. Planujemy kolonizację Marsa, a sztuczna inteligencja ma pomagać nam w rozwiązywaniu najbardziej złożonych problemów. Świat przyspiesza z ...

Wizualizacja danych
Nuty to nie muzyka. Jak zamienić liczby w historię, która naprawdę wybrzmiewa.
Hans Rosling, mistrz data storytellingu, powiedział kiedyś, że wizualizacja danych jest jak patrzenie na nuty — samo ich oglądanie nie ...
Polska w liczbach
Ogólnodostępne dane dotyczące Polski
Liczba ogólnodostępnych zbiorów danych jest w Polsce coraz większa — a liczba analiz, jakie można na ich podstawie wykonać, praktycznie ...